Până în acest moment, când am folosit expresiile "scriere din fișier" sau "citire din fișier", ne-am referit în mod exclusiv la fișiere de tip text.
Practic,
Spre deosebire de ele,
Ca de obicei, ambele metode de stocare au avantaje și dezavantaje care indică folosirea uneia sau a celeilalte în funcție de aplicație:
-
Stocarea sub formă text are ca principal avantaj formatul human readable al informației. Asta înseamnă că oricând putem să deschidem fișierul într-un editor și putem interpreta ce scrie în el direct, fără a mai avea nevoie de o altă aplicație. (
Exemplu: sursele de C ). Dezavantajul este că informația text ocupă mai mult decât în formă binară, și este greu de prelucrat de către programe. -
Stocarea sub formă binară are ca avantaje faptul că datele ocupă în medie (nu mereu) mai puțină memorie decât cele în format text, au structură previzibilă, dar cel mai important, pot fi încărcate direct în memorie. (
Exemplu: un binar executabil , care este de fapt imaginea din care este lansat un proces în execuție). Dezavantajul constă în faptul că ele devin complet neinteligibile pentru oameni (trebuie să le interpretăm cu o altă aplicație pentru a le înțelege).
Pentru că o imagine valorează cât o mie de cuvinte, vom ilustra grafic cum are loc reprezentarea efectivă în memorie a informațiilor în format text și binar. Fie următoarea structură de date care conține informații despre un elev.
typedef struct Elev{
short int nota1;
short int nota2;
char nume[10];
float medie;
} Elev;
[ ... main() și alte funcții ...]
Elev elev;
elev.nota1 = 7;
elev.nota2 = 10;
elev.medie = (elev.nota1 + elev.nota2) / 2.0;
strcpy(elev.nume, "Cartman");
Sa considerăm că avem două fișiere:
-
FILE* t = fopen("text.out","w"); , în care scriem conținutul acestei structuri în format text (așa cum am făcut până acum). Un exemplu de stocare este dat de următorul apel:
fprintf(t, "%d %d %f %s\n", elev.nota1, elev.nota2, elev.medie, elev.nume);
În realitate, fișierul arată în memorie astfel:
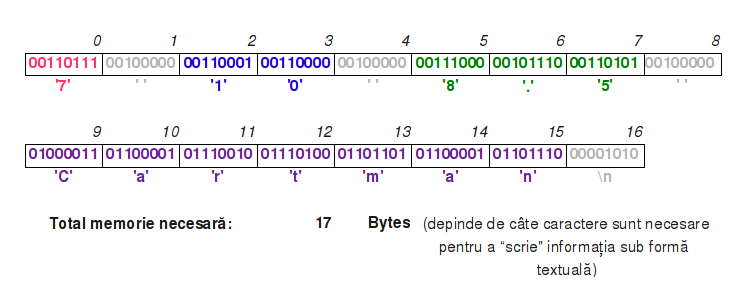
- În primul rând se observă că numerele nu se reprezintă pe un număr previzibil de caractere (ex: 1.1, 10.1, sau 10.333333333) care să depindă de tipul de dată.
- Pe de altă parte, trebuie să introducem caractere speciale de separație, ca să ne putem da seama unde se termină un număr și unde începe un altul.
- Cel mai important însă, dacă am vrea să citim aceste date din fișier, trebuie să interpretăm din nou șirul de caractere, să îl tăiem în segmente (după spații) și să transformăm bucățile individuale de șir în numere, unde este cazul. Nu vă lăsați păcăliți ca în loc de
-
FILE* b = fopen("binar.out","rb"); , în care scriem conținutul acestei structuri în format binar astfel:
fwrite(&elev, sizeof(Elev), 1, b);
În realitate, fișierul arată în memorie astfel:
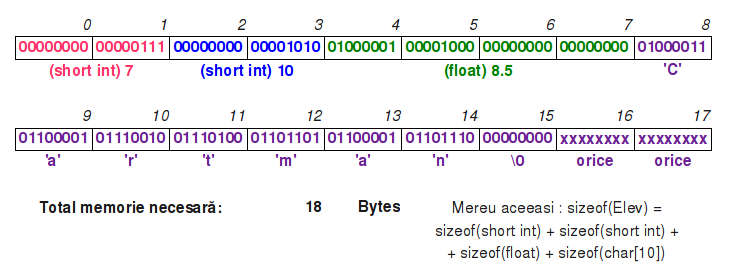
- În acest caz, datele se reprezintă pe un număr cunoscut de Bytes (mai exact, dimensiunea tipului de dată). După cum se vede din exemplu, asta nu înseamnă mereu că se ocupă mai puțină memorie. Cu toate acestea, în mod statistic, datele binare ocupă mai puțină memorie!
- O problemă este că dacă am vrea să deschidem fișierul pentru a citi aceste date, nu s-ar înțelege mai nimic, pentru că orice editor ar încerca să transforme fiecare Byte într-un caracter pe care să îl afișeze pe ecran. Evident, nu se obține ceea ce ne-am dori noi sa vedem. Avem nevoie de un program care să interpreteze fișierul și să ne arate conținutul din el.
- Din nou, cel mai important este că dacă am vrea să citim aceste date din fișier, le putem încărca direct la adresa unei structuri de tip